http请求 在可以进行网络通信之后,我们需要知道浏览器和我的服务器之间通信的规则\r\n,空行就是只有\r\n
请求行 请求行的格式为<method> <url> <version>method就是请求的方法包括GET,POST,OPTIONS,HEAD,PUT,
http响应 在服务器接受请求并进行一系列处理之后会构造一个http响应给浏览器,一个http响应的组成和http请求很像,一个响应行,后面接若干行响应报头,然后是一个终止报头的空行,再跟随一个响应体
响应行 响应行的格式为<version> <status code> <status message>参考
响应报头 最重要的两个报头就是Content-Type它告诉客户端响应主体中的内容的类型,以及Content-Length报头用来告诉客户端响应主体的字节大小
响应体 响应体就是被请求的内容
代码实现 读取一行 首先我们需要分析请求,因为http请求的每一行都是\r\n结尾的,我们可以写一个函数来一行一行的读入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 http_conn::READ_LINE_STATUS http_conn::HttpConn::readLine () { text.clear (); char c; http_conn::READ_LINE_STATUS statu=LINE_OPEN; while (statu==LINE_OPEN) { int isread=rio.rio_readnb (&riobuffer,&c,1 ); switch (isread) { case -1 : statu=LINE_BAD; break ; case 1 : statu=LINE_OPEN; if (c=='\n' ) { if (*text.rbegin ()=='\r' ) statu=LINE_OK; else statu=LINE_BAD; }else { if (*text.rend ()=='\r' ) statu=LINE_BAD; } text.append (1 ,c); break ; } } return statu; }
READ_LINE_STATUS是读取一行的状态,分别有三个为LINE_OK代表成功读取一行,LINE_OPEN代表正在读取一行,LINE_BAD代表读取错误即不是以\r\n结尾
处理请求 处理请求也有三种状态,处理请求行,处理请求头,处理请求体
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 http_conn::HTTP_CODE http_conn::HttpConn::parse_request () { while ((readlinestatus=readLine ())==LINE_OK) { switch (requestreadstatus) { case REQUEST_LINE: { HTTP_CODE ret=parse_requestline (); if (ret!=SUCCESS) { return ret; } break ; } case REQUEST_HEADER: { HTTP_CODE ret=parse_requesthead (); if (ret==BAD_REQUEST) return BAD_REQUEST; else if (ret==GET_REQUEST) { if (is_static) return parse_static_request (); else return parse_dynamic_request (); } break ; } case REQUEST_BODY: HTTP_CODE ret=parse_requestbody (); if (ret==BAD_REQUEST) return BAD_REQUEST; else if (ret==GET_REQUEST) { if (is_static) return parse_static_request (); else return parse_dynamic_request (); } break ; } } return BAD_REQUEST; }
requestreadstatus就是处理请求的三个状态,在每一个状态处理完之后会进行状态转移parse_requestline()
处理请求行 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 http_conn::HTTP_CODE http_conn::HttpConn::parse_requestline () { if (text.empty ()) return NO_REQUEST; std::stringstream ss (text) ; ss>>method>>uri>>version; transform (method.begin (), method.end (), method.begin (), ::toupper); if (method.compare ("GET" )!=0 &&method.compare ("POST" )!=0 ) { return NOT_IMPLEMENTED; } is_static=parse_uri (); requestreadstatus=REQUEST_HEADER; return SUCCESS; }
处理请求头 处理请求头的函数parse_requesthead()还没有具体实现,只是读进来
1 2 3 4 5 6 7 8 9 10 http_conn::HTTP_CODE http_conn::HttpConn::parse_requesthead () { if (text=="\r\n" ) { requestreadstatus=REQUEST_BODY; if (method=="GET" ) return GET_REQUEST; } return SUCCESS; }
处理请求体 处理请求体的函数parse_requestbody()同样还没具体实现
1 2 3 4 5 6 7 8 9 10 http_conn::HTTP_CODE http_conn::HttpConn::parse_requestbody () { if (text.empty ()) return GET_REQUEST; else { return SUCCESS; } }
分析url 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 int http_conn::HttpConn::parse_uri (){ if (uri.find ("cgi-bin" )==std::string::npos) { cgiargs="" ; filename="./static" ; filename+=uri; if (*uri.rbegin ()=='/' ) filename+="index.html" ; return 1 ; }else { int pos=uri.find ("?" ); if (pos!=std::string::npos) { cgiargs=uri.substr (pos+1 ); uri=uri.substr (0 ,pos); }else cgiargs="" ; filename="." ; filename+=uri; return 0 ; } }
其中cgiargs是处理动态资源的时候会用到,现在还用不到,默认静态资源放在程序同级目录的static文件夹下,动态资源放在cgi-bin文件夹下
处理静态请求(动态请求还未实现) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 http_conn::HTTP_CODE http_conn::HttpConn::parse_static_request () { struct stat sbuf; std::string filetype,buf; if (stat (filename.c_str (),&sbuf)<0 ) { return NOT_FOUND; } if (!(S_ISREG (sbuf.st_mode))||!(S_IRUSR&sbuf.st_mode)) { return Forbidden; } if (filename.find (".html" )!=std::string::npos) filetype="text/html" ; else if (filename.find (".gif" )) filetype="image/gif" ; else if (filename.find (".jpg" )) filetype="image/jpeg" ; else filetype="text/plain" ; std::stringstream ss; ss<<"HTTP/1.0 200 OK\r\n" ; ss<<"Server: Time Web Server\r\n" ; ss<<"Content-length: " <<sbuf.st_size<<"\r\n" ; ss<<"Content-type: " <<filetype<<"\r\n\r\n" ; buf=ss.str (); rio.rio_writen (connfd,(char *)buf.c_str (),sbuf.st_size); int filefd=open (filename.c_str (),O_RDONLY,0 ); char *usrbuf=(char *)malloc (sbuf.st_size+2 ); RIO::rio_t readbuf (filefd) ; rio.rio_readn (filefd,usrbuf,sbuf.st_size); rio.rio_writen (connfd,usrbuf,sbuf.st_size); free (usrbuf); close (filefd); return SUCCESS; }
处理错误信息 对于失败的请求我们要返回错误信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 void http_conn::HttpConn::parse_error (){ std::stringstream ss; std::string errnum;std::string errmsg,longmsg; switch (requeststatuscode) { case SUCCESS: case NO_REQUEST: case GET_REQUEST: break ; case BAD_REQUEST: errnum="400" ; errmsg="Bad Request" ; longmsg="The request could not be understood by the server due to malformed syntax" ; break ; case Forbidden: errnum="403" ; errmsg="Forbidden" ; longmsg="The server understood the request, but is refusing to fulfill it" ; break ; case NOT_FOUND: errnum="404" ; errmsg="NOT_FOUND" ; longmsg="The server has not found anything matching the Request-URI" ; break ; case NOT_IMPLEMENTED: errnum="501" ; errmsg="NOT_IMPLEMENTED" ; longmsg="The server does not support the functionality required to fulfill the request" ; break ; } std::string body="<html><title>Server Error</title>" ; body+="<body bgcolor=" "ffffff" ">\r\n" ; body+=errnum+": " +errmsg+"\r\n" ; body+="<p>" +longmsg+": " +filename+"\r\n" ; body+="<hr><em>The Time Web Server</em>\r\n" ; ss<<"HTTP/1.0 " <<errnum<<" " <<errmsg<<"\r\n" ; ss<<"Content-type: " <<"text/html\r\n" ; ss<<"Content-length: " <<body.size ()<<"\r\n\r\n" ; ss<<body; body=ss.str (); rio.rio_writen (connfd,(char *)body.c_str (),body.size ()); }
初始化 我们最后实现初始化这个类HttpConn
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void http_conn::HttpConn::init (){ requestreadstatus=REQUEST_LINE; requeststatuscode=NO_REQUEST; listenfd=M_SOCKET::MySocket::openListenfd (8888 ); struct sockaddr_in clientaddr; unsigned int clientlen=sizeof (clientaddr); connfd=accept (listenfd, (sockaddr*) &clientaddr,&clientlen); rio.rio_readinitb (&riobuffer,connfd); requeststatuscode=parse_request (); if (requeststatuscode!=SUCCESS) { parse_error (); } close (connfd); }
为了测试先这样写,之后肯定会改的
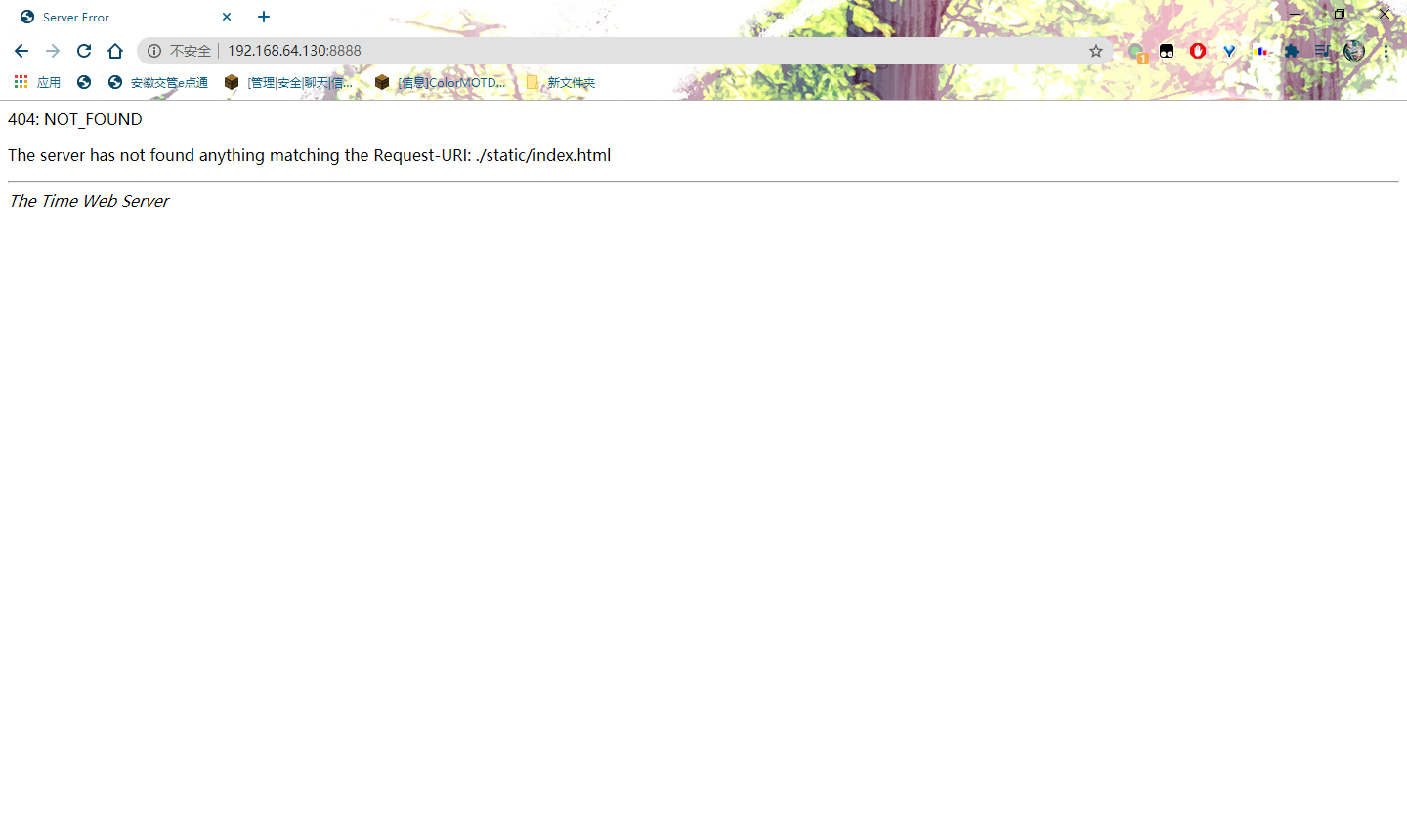
测试 我没放文件返回了404
类的定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #ifndef __HTTP__CONN_H__ #define __HTTP__CONN_H__ #include <http_server.h> #include "rio.h" #include "my_socket.h" #include "http_server.h" #include <sstream> #include <algorithm> #define MAXLINE 1024 namespace http_conn{ enum HTTP_CODE {NO_REQUEST=0 ,GET_REQUEST=1 ,SUCCESS=200 ,BAD_REQUEST=400 ,Forbidden=403 ,NOT_FOUND=404 ,NOT_IMPLEMENTED=501 }; enum READ_LINE_STATUS {LINE_OK=1 ,LINE_BAD=-1 ,LINE_OPEN=0 }; enum REQUEST_READ_STATUS {REQUEST_LINE,REQUEST_HEADER,REQUEST_BODY}; class HttpConn { private : RIO::rio_t riobuffer; RIO::Rio rio; HTTP_CODE requeststatuscode; READ_LINE_STATUS readlinestatus; REQUEST_READ_STATUS requestreadstatus; std::string method,uri,version,filename,cgiargs; std::string text; int is_static; int listenfd; int connfd; READ_LINE_STATUS readLine () ; HTTP_CODE parse_requestline () ; HTTP_CODE parse_requesthead () ; HTTP_CODE parse_requestbody () ; HTTP_CODE parse_request () ; HTTP_CODE parse_static_request () ; HTTP_CODE parse_dynamic_request () ; void parse_error () int parse_uri () public : void init () }; } #endif